


Note
Click here to download the full example code
Quick Start with PyTorch¶
In this tutorial, we demonstrate how to do Hyperparameter Optimization (HPO) using AutoTorch with PyTorch. AutoTorch is a framework agnostic HPO toolkit, which is compatible with any training code written in python. The code used in this tutorial is adapted from this git repo. In your applications, this code can be replaced with your own PyTorch code.
Import the packages:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
from tqdm.auto import tqdm
Start with an MNIST Example¶
Data Transforms
We first apply standard image transforms to our training and validation data:
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
# get the datasets
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
Out:
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to ./data/MNIST/raw/train-images-idx3-ubyte.gz
Extracting ./data/MNIST/raw/train-images-idx3-ubyte.gz to ./data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to ./data/MNIST/raw/train-labels-idx1-ubyte.gz
Extracting ./data/MNIST/raw/train-labels-idx1-ubyte.gz to ./data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to ./data/MNIST/raw/t10k-images-idx3-ubyte.gz
Extracting ./data/MNIST/raw/t10k-images-idx3-ubyte.gz to ./data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to ./data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting ./data/MNIST/raw/t10k-labels-idx1-ubyte.gz to ./data/MNIST/raw
Processing...
Done!
Main Training Loop
The following train_mnist function represents normal training code a user would write for training on MNIST dataset. Python users typically use an argparser to conveniently change default values. The only additional argument you need to add to your existing python function is a reporter object that is used to store performance achieved under different hyperparameter settings.
def train_mnist(args, reporter):
# get variables from args
lr = args.lr
wd = args.wd
epochs = args.epochs
net = args.net
print('lr: {}, wd: {}'.format(lr, wd))
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# Model
net = net.to(device)
if device == 'cuda':
net = nn.DataParallel(net)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=args.lr, momentum=0.9, weight_decay=wd)
# datasets and dataloaders
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2)
# Training
def train(epoch):
net.train()
train_loss, correct, total = 0, 0, 0
for batch_idx, (inputs, targets) in enumerate(trainloader):
inputs, targets = inputs.to(device), targets.to(device)
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
def test(epoch):
net.eval()
test_loss, correct, total = 0, 0, 0
with torch.no_grad():
for batch_idx, (inputs, targets) in enumerate(testloader):
inputs, targets = inputs.to(device), targets.to(device)
outputs = net(inputs)
loss = criterion(outputs, targets)
test_loss += loss.item()
_, predicted = outputs.max(1)
total += targets.size(0)
correct += predicted.eq(targets).sum().item()
acc = 100.*correct/total
reporter(epoch=epoch, accuracy=acc)
for epoch in tqdm(range(0, epochs)):
train(epoch)
test(epoch)
AutoTorch HPO¶
In this section, we cover how to define a searchable network architecture, convert the training function to be searchable, create the scheduler, and then launch the experiment. - Define a Searchable Network Achitecture
Let’s define a ‘dynamic’ network with searchable configurations by simply adding a decorator autotorch.obj(). In this example, we only search two arguments hidden_conv and hidden_fc, which represent the hidden channels in convolutional layer and fully connected layer. More info about searchable space is available at autotorch.space().
import autotorch as at
@at.obj(
hidden_conv=at.Int(6, 12),
hidden_fc=at.Choice(80, 120, 160),
)
class Net(nn.Module):
def __init__(self, hidden_conv, hidden_fc):
super().__init__()
self.conv1 = nn.Conv2d(1, hidden_conv, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(hidden_conv, 16, 5)
self.fc1 = nn.Linear(16 * 4 * 4, hidden_fc)
self.fc2 = nn.Linear(hidden_fc, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 16 * 4 * 4)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
Convert the Training Function to Be Searchable
We can simply add a decorator autotorch.args() to convert the train_mnist function argument values to be tuned by AutoTorch’s hyperparameter optimizer. In the example below, we specify that the lr argument is a real-value that should be searched on a log-scale in the range 0.01 - 0.2. Before passing lr to your train function, AutoTorch always selects an actual floating point value to assign to lr so you do not need to make any special modifications to your existing code to accommodate the hyperparameter search.
@at.args(
lr = at.Real(0.01, 0.2, log=True),
wd = at.Real(1e-4, 5e-4, log=True),
net = Net(),
epochs=5,
)
def at_train_mnist(args, reporter):
return train_mnist(args, reporter)
Create the Scheduler and Launch the Experiment
scheduler = at.scheduler.FIFOScheduler(at_train_mnist,
resource={'num_cpus': 4, 'num_gpus': 1},
num_trials=2,
time_attr='epoch',
reward_attr="accuracy")
print(scheduler)
scheduler.run()
scheduler.join_jobs()
Out:
FIFOScheduler(
DistributedResourceManager{
(Remote: Remote REMOTE_ID: 0,
<Remote: 'inproc://172.31.37.77/16822/1' processes=1 threads=8, memory=64.38 GB>, Resource: NodeResourceManager(8 CPUs, 1 GPUs))
})
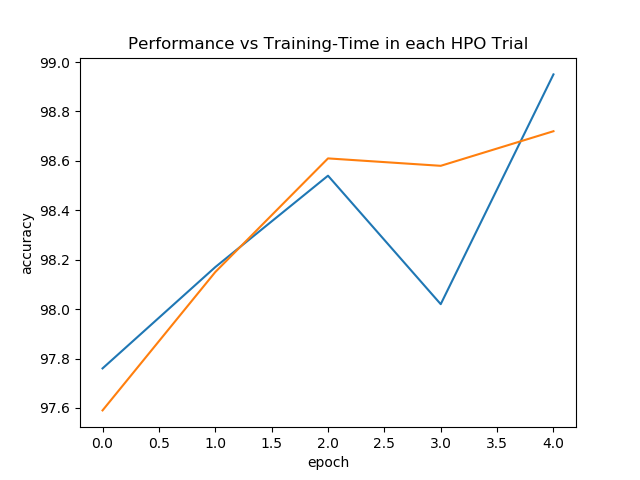
We plot the test accuracy achieved over the course of training under each hyperparameter configuration that AutoTorch tried out (represented as different colors).
scheduler.get_training_curves(plot=True,use_legend=False)
print('The Best Configuration and Accuracy are: {}, {}'.format(scheduler.get_best_config(),
scheduler.get_best_reward()))
Out:
The Best Configuration and Accuracy are: {'lr': 0.0447213595, 'net.hidden_conv': 9, 'net.hidden_fc.choice': 0, 'wd': 0.0002236068}, 98.95
Total running time of the script: ( 1 minutes 20.652 seconds)